Cambridge Analytica & Facebook
last update: 19 Nov. 2019
These are some recent links to articles that have not yet been integrated into this story:
The NSA confirms it: Russia hacked French election 'infrastructure', Wired, 9 May 2017
Conservative Twitter is freaking out over a reported bot purge, The Verge, 21 Feb. 2018
The Era of Fake Video Begins, The Atlantic, 8 April 2018
Mark Zuckerberg: “We do not sell data to advertisers”, TechCrunch, 10 April 2018
Transcript of Mark Zuckerberg’s Senate hearing, The Washington Post, 10 April 2018
Zuckerberg struggles to name a single Facebook competitor, The Verge, 10 April 2018
Five things the world finally realises about Facebook, Quartz, 11 April 2018
How To Avoid Being Tracked Online, Gizmodo, 11 April 2018
Mark Zuckerberg vows to fight election meddling in marathon Senate grilling, The Guardian, 11 April 2018
3 more claims that point to Vote Leave cheating, INFacts, 13 April 2018
Facebook to ask everyone to accept being tracked so they can keep using it, The Independent, 18 April 2018
Facebook to exclude billions from European privacy laws, BBC News, 19 April 2018
'Facebook in PR crisis mode', says academic at heart of row, BBC News, 24 April 2018
Twitter sold data to Cambridge Analytica - data sales account for 13% of revenue, Flipboard, 30 April 2018
Cambridge Analytica's Major players: Where are they now? Fast Company, 2 May 2018
Cambridge Analytica shutting down after Facebook data scandal, MacRumors, 3 May 2018
Facebook, Twitter, and Google would like to be the Gatekeepers of Democracy, without the responsibility, Gizmodo, 4 May 2018
Tech watchdogs call on Facebook and Google for transparency around censored content, TechCrunch, 7 May 2018
Congress releases all 3,000-plus Facebook ads bought by Russians, c|net, 10 May 2018
Facebook has suspended around 200 apps so far in data misuse investigation, The Verge, 14 May 2018
The DOJ and FBI are now reportedly investigating Cambridge Analytica, Gizmodo, 15 May 2018
Facebook details scale of abuse on its site, BBC News, 15 May 2018
It would appear that Facebook employs 15,000 human moderators, but that its algorithms struggle to spot some types of abuse. Apparently they detect 99.5% of terrorist propaganda, but only 38% of hate speech. Facebook also said it had in a 3 month period taken down 583 million fake accounts.
Cambridge Analytica whistleblower warns of 'new Cold War' online, Politico, 16 May 2018
This article from Politico could merit an extended development in that it would appear that Cambridge Analytica had close links with both Julian Assange, founder of Wikileaks, and that they used "Russian researchers, shared information with Russian companies and executives tied to the Russian intelligence".
Scandal-ridden Cambridge Analytica is gone but its staffers are hard at work again, Quartz, 16 June 2018
Data Propria (see also this Wired article from 29 May, 2018, on where staff from Cambridge Analytica have landed)
Facebook, Twitter are designed to act like 'behavioural cocaine', cnet, 4 July 2018
Facebook scandal: Who is selling your personal data? BBC, 11 July 2018
Article looks at role of data brokers such as Acxiom and Experian.
Four intriguing lines in Mueller indictment, BBC, 13 July 2018
This article mentions DCLeaks and Guccifer 2.0 as being fronts for Russian military intelligence, and famous "Russian if your listening…" comment of Trump.
Twelve Russians charged with US 2016 election hack, BBC, 13 July 2018
Donald Trump is the biggest spender of political ads on facebook, The Wrap, 18 July 2018
He has spent $274,000 on ads in a 2-3 month period, thats 9,500 ads in 2 months.
Inside Bannon's Plan to Hijack Europe for the Far-Right, Daily Beast, 20 July 2018
It would appear that Bannon wants to set-up a European foundation called The Movement to help right-wind populist parties.
Hackers 'targeting US mid-term elections', BBC, 20 July 2018
Three candidates have already been attacked using domains known as ''Fancy Bear'.
https://www.bbc.com/news/technology-64075067
Give the complexity of the topic treated in these pages what I’ve decided to do is to add here six videos. They can be viewed before reading the text as a way to pre-brief yourself, or you can wait to view them within the context of the text itself.
Start with the keynote The End of Privacy by Dr. Kosinski (March 2017), and then have a look at The Power of Big Data and Psychographics by Mr. Alexander Nix of Cambridge Analytica (Sept. 2016). Then we have Cambridge Analytica explains how the Trump campaign worked (May 2017). Now turn to The Guardian interview (March 2018) with Christopher Wylie, the Cambridge Analytica whistleblower, giving evidence to UK MP’s (March 2018). And finally spend a moment to listen to Steve Bannon on Cambridge Analytica (March 2018).
Be warned, this story is as much about ‘fake news’, disinformation, psychometrics, Facebook and its ‘social graph’, and privacy, as it is about Cambridge Analytica.
During March-April 2018 the Cambridge Analytica - Facebook story often occupied the front pages of the mainstream press. Perhaps because of the technical nature of the story, perhaps because of time and space constraints, many of the details were mashed together or just overlooked. Coverage in the specialist press was more complete, but again not always perfectly tied together. My interest has always been in the technical aspects, but this story is in many ways more about social engineering and modern but opaque business practices.
In any case I have tried here to capture the complete story, but one still can’t be sure that all the facts are out in the open (or even which are fact and which fiction). In addition I have tried to add some recent contextual elements, and even some elements that may or may not prove with time to be important. I am certain that my text will occasionally look longwinded and even overly detailed. I’m sorry for that, but I found it very difficult to “see the wood for the trees”, particularly when you don’t really know which trees are important anyway.
Here goes!
Setting the scene
Lets start at the beginning, Over the past 18-24 months numerous articles have appeared about people (read Russians) trying (and maybe succeeding) to influence or manipulate the US presidential elections and the ‘BREXIT’ referendum in the UK. But the reality is they have been active all over Europe.
Recently in the Italian national elections 2018
Recently the pro-European, centre-left El País ran an article about how Kremlin-backed media outlets promoted a xenophobic discourse during the 2018 Italian national elections.
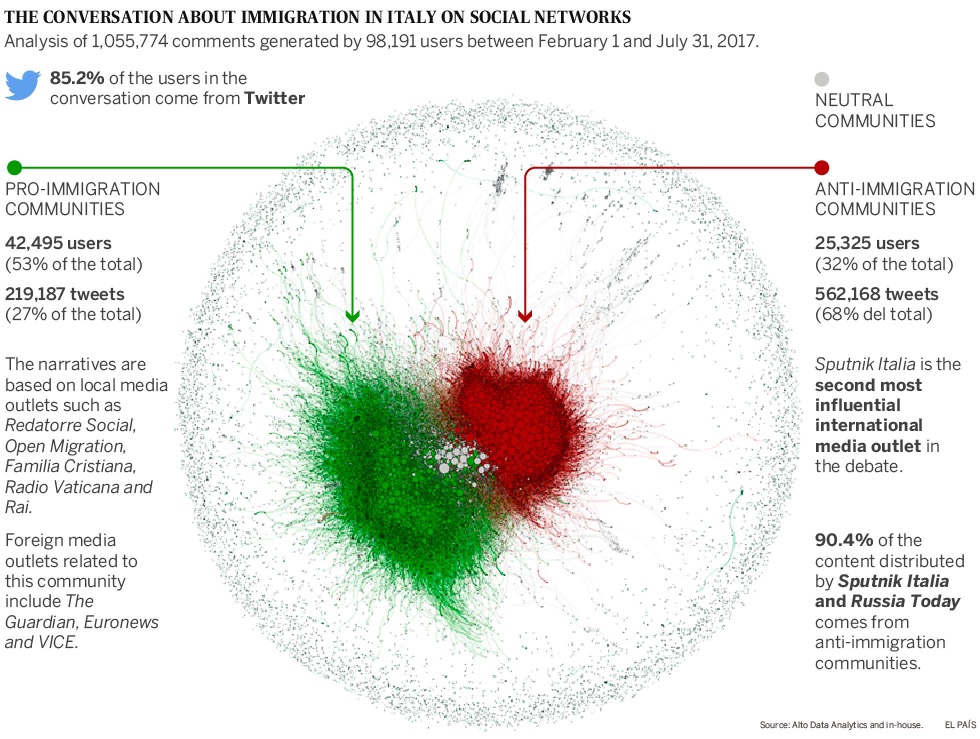
This was presented in the specialist press as a perfect example of modern-days disinformation. Anti-immigration and anti-NGO activists shared stories published by RT and Sputnik, Russian government controlled news platforms (see this US Intelligence Report). The key message was that Italy had been invaded by refugees, and they were to blame for unemployment and inflation. And that European politicians were ultimately responsible.
You may think that this type of blatant disinformation will not work. However an analysis of more than 3,000 news sources over a 6-month period in 2017 showed that Sputnik was the second most influential foreign media source operating in Italy, after the liberal-inclined The Huffington Post. Sputnik was helped by a series of bots (more precisely bot farms) that continuously re-published anti-immigration comments.
The technique is simple (and clearly effective) and involves using questionable sources, biased experts and sensationalist headlines, all shared across 1,000’s of social network accounts. The aim, to make the content go viral, and thus to amplify the perception of the problem. Sputnik provided the content which was then shared by profiles who regularly disseminated anti-immigration messages. Immigration was linked to insecurity, crime and terrorism.
The El País article explained that Russia cultivated both ends of the political spectrum in Italy. The aim is to break the trade embargoes against Russia and “foster cooperation in areas of security, defence of traditional values and economic cooperation”, which is another way to say weaken existing EU, NATO and transatlantic alliances. These ideas have also been expressed by right-wing political parties in France, Hungary and Austria, and by the far-left in Greece.
We must remember that disinformation, as used by the Russians in Italy, reinforces misperceptions and misunderstandings, provokes and exploits existing problems, and generally engenders social disagreement and disaccord. Italy had, many would say still has "38% youth unemployment, a stagnating economy, a record debt load, endemic corruption, rising political apathy and dissatisfaction with traditional political parties, and a problem of immigration". Disinformation did not create these problems, it exploited them, it spun and twisted them, and it tried to foster an unhealthy and distorted debate on how to address them. I might add that the above quote came from an article in the very reputable sounding Strategic Culture Foundation ("focussing on hidden aspects of international politics and unconventional thinking"), which WikiSpooks defines as a Moscow-based anti-Zionist think tank and web publishing organisation.
At the end of the day who can you believe? Which media sources can be trusted? Malcolm X once said that the (mainstream) media controlled the minds of the masses but today the media can't decide whether they are in the business of reporting news or manufacturing propaganda, and frankly most people don't understand the difference. I can't remember who first said it but today both the mainstream media and social networks are in the business of "liquidification of meaning", and there are fewer and fewer solid "islands of truth" left.
Before that in the Catalonian independence referendum 2017
It is claimed that the same technique was used in the recent illegal referendum in Catalonia. Pro-independence messages and fake news were propagated by Russian news sources, which were then amplified via 10,000’s of profiles on social networks (including 1,000’s of profiles with Venezuelan accounts). There is evidence that this type of social conversation can sway public opinion. This disinformation appeared in the days preceding the referendum, and the Spanish State, the traditional political parties, and the usual mass-market media outlets did not manage to create an effective reply. In the days prior to the referendum nearly 80% of messages on social media defended the independence of Catalonia (it was estimated that more than 80% of those massages were from false profiles or bots). The message was clear, the Spanish police acted violently against peaceful Catalan citizens, and the Spanish State was a repressive Franco-like regime. It has been estimated that the combined messages of the two Russian State media outlets (and including the Russian linked Spanish language El Espía Digital) were 10 times more influential that both the centre-right El Mundo and Catalonia’s leading newspaper La Vanguardia. Yet Putin is quoted as saying that Catalan independence is “an internal matter for Spain”. The key is again is to sow dissent and discord by playing both sides, possibly with the longer term objective to see a strong Spanish far-right party emerge along the lines of VOX. There was also an undercurrent in the separatist media that the results of the Catalan referendum would legitimised the annexation/self-determination of the Crimean peninsula. And to top it all some of the pro-independence online activity came out of the US. David Knight on the 'fake news' pro-Trump InfoWars claimed that 700 mayors had been arrested in Spain and that the Spanish government was preparing to invade Catalonia by sea (he also criticised Trump for not supporting Catalan self-determination). The conservative pro-Trump Drudge Report also promoted Catalan independence to their 19 million subscribers. There was even a report that Russian hackers helped keep open census websites for the Catalan regional government.
Again disinformation did not create the strong ethnopolitical polarisation between Catalonia and Spain, it just tried to reinforce it and exploit it.
And before that in the US Presidential campaign 2016
Without dwelling too much on the recent US Presidential campaign Russian interference used the same basic approach. Sources were found, or created, that reinforced a particular claim or position. Those sources were given headline space, and re-published, and then often picked up by news services around the world. A stream of interactions on Facebook and Twitter convinced people about the truth, or at least newsworthiness of the sources. No one checked to see if the Pope had really said that US Catholics should vote to make America strong and free again. No one checked to see that 70% or 80% of the traffic on Facebook and Twitter came out of bot farms. Yet during the elections 60% of Americans claimed to use Facebook to help keep themselves informed. At that time identifying ‘newsworthy’ items on Facebooks was largely driven by algorithms that rewarded reader engagement above all else, and were thus almost designed to help make certain sensationalist news items go viral.
Through 2017 Facebook now employs more than 7,500 people to monitor video and news streams that are reported as inappropriate by their users (YouTube has 10,000 people working on this). However the ‘content moderators’ rightly prioritise pornography, terrorism, violence, and abnormal/Illegal behaviour, rather than ‘fake news’. But even then there are abundant examples of inappropriate content remaining on social networks for months before finally being taken down. YouTube has said it is using machine learning algorithms to help its content moderators to remove around 300,000 videos per year just in the category ‘violent extremism’. But most experts think that this is just ‘the tip of the iceberg'.
This story is about Cambridge Analytica and Facebook, but what exactly is Facebook?
If you read Wikipedia it tells us that Facebook is a social networking service. Zuckerberg tells us “people come to Facebook, Instagram, Whatsapp, and Messenger about 100 billion times a day to share a piece of content or a message with a specific set of people”. Some experts tell us that Facebook could easily rank as the largest online publisher in the world, and it’s advertising-driven for-profit perspective is no different from any of its mass media predecessors. Others might say that with its “f” everywhere it is a vast branded utility, serving ‘useful content’ rather than litres or kWatts. Yet others think of Facebook as a kind of closed World Wide Web designed to make as much money as possible. A few people have even suggested that it is similar to the cigarette industry, in that it is both addictive and bad for you. A more sensible idea, given that Facebook serves one in four of every ad displayed on the Web, is to consider it an advertising company. Facebook's advertising revenue was over $9 billion for Q2 2017, and they capture 19% of the $70 billion spent annually on mobile advertising worldwide.
Facebook has more than 1.3 billion daily active users, and more importantly over 1 billion mobile daily active users (85% of them outside the US and Canada). This is important because mobile advertising revenue represents 88% of their total advertising revenue. Mobile users access Facebook on average 8 time per day, and oddly enough brands post something new or updates an average of 8 times per day. The ‘like’ and ’share’ buttons are viewed across more than 10 million websites daily. People spend more than 20 minutes a day on Facebook, upload well in excess of 350 million photographs daily (adding to the 250 billion already uploaded), and post in excess of 500,000 comments every minute. Daily well over 5 billion items are shared, and over 8 billion videos are viewed, however the average viewing time per video is only 3 seconds. You often hear that Facebook is for old people, but 83% of users worldwide are under 45 years old, and men 18-24 make up the biggest sector of users (18%). Watching videos on mobile devices appears to have the highest engagement rate, but 85% of users watch with the sound off!
The average Facebook user has 155 friends, but would trust only four of them in a crisis. On the other hand 57% of users say social media influences their shopping habits. The average click-through rate for Facebook ads across all sectors is 0.9%, and oddly enough the highest click-through is in the legal sector and the lowest in employment and job training. Pay-per-click, the amount paid to Facebook by advertisers, is highest for financial services and insurance ($3.77) and lowest for clothing ($0.45), the average is $1.72.
There is an old adage that if you are not paying for it, you are the product. This is nowhere more true than with Facebook. US and Canadian users are the most valuable to Facebook, each generating on average over $26 revenue in Q4 2017, just from advertising. For the US and Canada it was $85 annually per regular user for 2017, but for Europe it was only about $27 annually.
At the end of 2017 Facebook was using 12 server centres, 9 in the US and 3 in Europe (2 more are planned for the US). They are the 3rd busiest site on the Internet (after Google and YouTube). I understand that Facebook started by leasing ‘wholesale’ data centre space, but they now own at least 6 server farms. At the end of 2015 Facebook reported that it owned about $3.6 billion in network equipment, and spent about $2.5 billion on data centres, servers, network infrastructure and offices. In 2013 it was estimated that each Facebook data centre was home to 20,000 to 26,000 servers, but I have seen figures quoted for new data centres with 30,000 to 50,000 servers. Facebook does not publish the total number of servers they run, but estimates have been made based on the surface areas (5,000 servers per 10,000 sq.ft) and on the power and water consumption of the server farms, and the figure could be anything between 300,000 to 400,000. The storage capacity of Facebook data centres has been estimated at 250 petabytes.
For the more technical minded reader Facebook created BigPipe to dynamically serve pages faster, Haystack to efficiently store billions of photos, Unicorn for searching the social graph, TAO for storing graph information, Peregrine for querying, and MysteryMachine to help with end-to-end performance analysis. And if you are a real techno-fanatic have a look at Measuring and improving network performance (2014) which will give you and insight into the challenges in providing the Facebook app to everyone, everywhere, all the time.
Facebook and ‘fake news'
Facebook has been criticised for failing to do enough to prevent it being misused for ‘fake news’, Russian election interference and hate speech. Today each time someone from Facebook talks about ‘fake news’ they mention artificial intelligence. Some types of image recognition are already being used, e.g. using face recognition to suggest a friends name in a picture. Already in 2014 they reported a more than 97% accuracy. The move today is to so-called ‘deep learning’ where the systems are taught to recognise similarities and differences in areas such a speech recognition, image recognition, natural language processing, and user profiling. Check out Facebook's page and videos here. This is not only about identifying people in photographs or videos, but about also understanding what they are doing, and identifying surrounding objects. They are also looking at language understanding, the use of slang, and the use of words with multiple meanings. The up-front claim is that this will help identify offensive content, filter out click-bait, and identify propaganda, etc. But at the same time it will help better match advertisers to users and identify trending topics, what Facebook calls “improving the user experience”.
Behind their sales pitch on artificial intelligence, Facebook are actually re-developing their hardware and software infrastructure to support machine learning. Pushing a sizeable portion of their data and workload through machine learning pipelines implies both a GPU and CPU infrastructure for processing training data, and the need for an abundant CPU capacity for real-time inference. In practice machine learning is used for ranking posts for news feeds, spam detection, face detection and recognition, speech recognition and text translation, and photo and real-time video classification. And not forgetting the need to determine (predict) which ad to display to a given user based upon user traits, user context, previous interactions, and advertisement attributes.
Facebook, an example of surveillance capitalism
We should never forget that Facebook solicits social behaviours, monitors those behaviours, maps social interactions (socio-mapping), and resells what they learn to advertisers (and others). This is the definition of surveillance capitalism. Authors on this topic have a nice way of introducing the topic with “Governments monitor a small number of people by court order. Google monitors everyone else”. In this form of capitalism, human nature is the free raw material. The ’tools of production’ are machine learning, artificial intelligence, and algorithms for big data. The ‘manufacturing process’ is the conversion of user behaviour into prediction products, which are then sold into a kind of market that trades exclusively in future behaviour. Better predictions are the product, they lower the risks for sellers and buyers, and thus increase the volume of sales. Once big profits were in products and services, then big profits came from speculation, now big profits come from surveillance, the market for future behaviour. We should not forget that behaviour is not limited to human behaviour - bodies, things, processes, places, … all have a behaviour that can be packaged and sold. But what of the rights of the individual to identity, privacy, etc.? The surveillance economy does not erode those rights, it redistributes them. Capital, assets, and rights are redistributed, and some people will have more rights, other less, creating a new dimension of social inequality. Do we have a system of consent for this new type of capitalism? Is there a democratic oversight of surveillance capitalism, in the form of laws and regulations?
Farfetched, maybe, but some experts see ‘automotive telematics’ as the next Google and another perfect example of surveillance capitalism. Automotive data can be used for dynamic real-time behaviour modification, triggering punishment (real-time rate hikes, financial penalties and fines, curfews, engine lock-downs) or rewards (rate discounts, coupons, points to redeem for future benefits). Insurance companies will be able to monetise customer driving data in the same way Google sells search activity. What Google, Twitter, Facebook, etc. do (and what everyone else wants to do) is sell access to the real-time flow of peoples daily lives, and better still modify peoples behaviour, for profit. If you think surveillance capitalism farfetched, have a look at Social Media Surveillance: Who is Doing It?, and if you still don’t believe it check out the “logical conclusion of the Internet of Things”.
Facebook's ‘social graph'
Facebook’s core tool for surveillance capitalism is its social graph. Here is a technical video presentation on the social graph, and here is a more business oriented presentation on the same topic (both from 2013). The social graph is often presented as one of the 3 pillars of Facebook, along with News Feed and the Timeline. In simple terms a social graph is composed of people, their friendships, subscriptions, likes, posts, and all the other types of logical connections. However for Facebook this means real world graphs at the scale of hundreds of billions of edges (an ‘edge’ is just a link or line between two ‘nodes’ in a graph). Below we can see just the ‘edges’ or lines drawn (relationships) between one particular user and their top 100 Facebook ‘friends’.
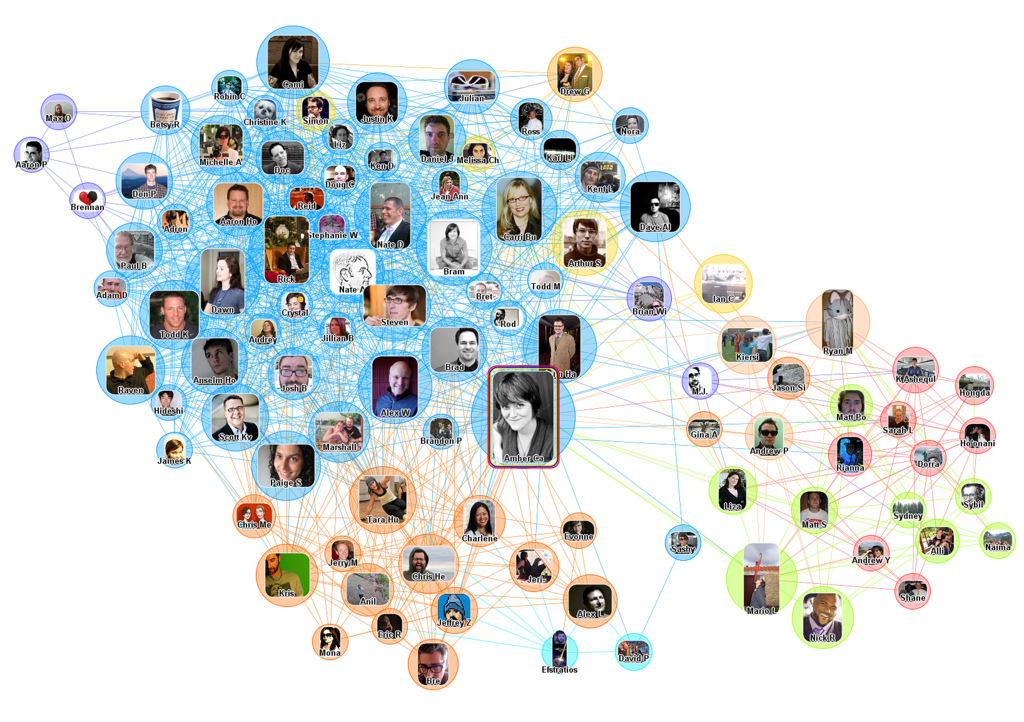
So the social graph actually represents a persons online identity, and of course Facebook maintains the worlds largest social graph. Naturally Facebook sees your social graph as a commercial asset, and they do not allow users to ‘export’ it to an alternative social network. In the past there were apps that mapped a persons social graph, but many have now been dis-activated. Below we have one persons actual Facebook social graph captures in 2011.

As a Facebook user you can't login and see your social graph. Facebook’s interface is carefully designed to renders invisible the processes by which the company profits from users’ interactions. Like firms such as Google, Facebook invites its users to exchange their personal information for the value they gain from using the service. Its interface is designed to maximise social interaction in a way that also maximises profits for the firm. In the past era of industrial capitalism this kind of exchange would have been managed by contract. In the era of surveillance capitalism, companies like Facebook manage the exchange of social information primarily by designing a semiotic environment, the interface. These environments carefully and deliberately shape the behavioural options for users. They have become what some experts call “choice architectures”, conglomerations of algorithms, texts and images designed not to tell a user what to do, but to subtly solicit a desired behaviour (and populate Facebook’s ‘social graph’).
In essence, Facebook sells advertisers on the idea that their ads will reach potential customers with a high likelihood of buying their products. To ascertain that likelihood, Facebook asks advertisers to define potential customer segmentation metrics. At the same time, Facebook surveils its users, abstracting patterns of interaction among them, and developing them into a rich ‘topological space’ or social graph, but one that pays no attention to other aspects of the life of the underlying users. Facebook maps and quantifies patterns of interaction and explores their association with particular behavioural outcomes. By recognising patterns and calculating relationships in real time, Facebook is able to infer the probability that a certain segment of their user population will be drawn to a particular community, action or product. It is essentially this inference that they sell to advertisers.
If you are attracted to the ideas behind a social graph, and/or to the intriguing graphics, check out visual complexity which is all about visualising complex networks.
Developers can get access to Facebook’s social graph through a kind of ‘back-door’ using Open Graph and the Graph API. What a developer does is to markup their website so that the Facebook Crawler can capture the title, description and preview image of the content. Then they need to register and configure the app, and submit it for review. Beyond that Facebook provides lots of guidance and a full software development kit.
How can you see your ‘social graph’?
This section is reserved from those who want to access, copy, view and even analyse a Facebook ‘social graph’. These are just starters to point the reader at a few tools that are out there. Frankly with all the problems that Facebook, Twitter, etc. are facing I’ve no idea if these tools will still work in the future. They worked when I tested them in April-May 2018.
We will start with Netvizz, here is a useful how to video. Firstly you need to open Facebook with Chrome or Firefox (not Safari). Secondly you need to find and load the app Netvizz (I found version 1.45). We will select the ‘page like network’. You will need to go to the page ids (Lookup-ID.com) and use the target Facebook profile URL. I picked 'Spain Is Different' with the URL ‘https://www.facebook.com/spain.likemag' to obtain the numerical ID ‘seed’ 558169620983049. You input the ‘seed’ and the depth (1 or 2) and ‘start’. This will download a zip file entitled pagenetwork_nnnn….zip which you unzip to obtain a .gdf file. Now you will need to visualise the ‘social graph’ with, for example, Gephi. Opening Gephi and opening the .gdf file will produce a rather simple ‘social graph’ for this particular example.
Next we have TouchGraph which is a visualisation and analytics tool, but one that can be integrated with consulting services. A simple trial produced the below visualisation of three terms, which in itself can lead to some interesting questions, e.g. why is it that in their recent articles only the New York Times still links 'fake news' with both Cambridge Analytica and Facebook?
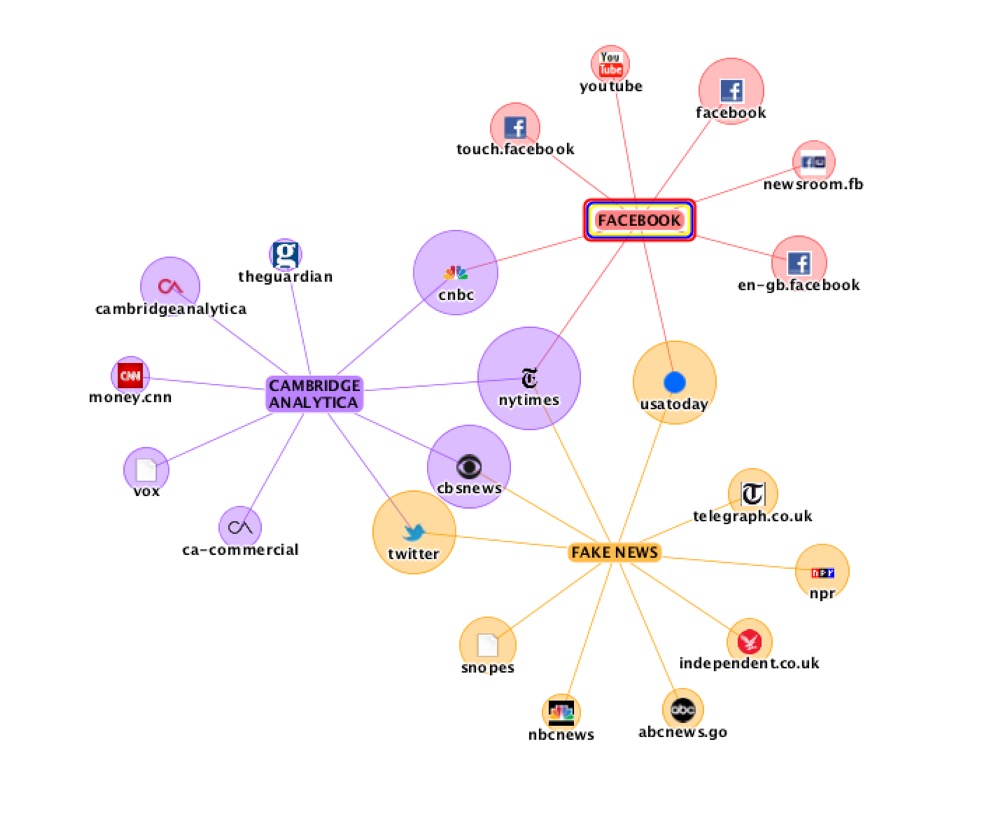
TouchGraph's Facebook Browser (i.e. TouchGraph Photos) which in the past could visualise your friends and their shared photographs is no longer available.
The next one is NameGenWeb which now produced a blank page "due to changes to the Facebook API and the lack of funding to support continued development, we regret to announce that NameGenWeb will be offline for the foreseeable future".
Then we have Friend Wheel which already in September 2015 had to close down due to a change in the Facebook API caused by a revision of their privacy rules.
Facebook Friends Constellation was also a tool used to visualise relationships on Facebook, but it has completely disappeared.
Meurs Challenger is also a graph visualisation tool which still offers a 'friends visual map' for Facebook (I was not able to check it out because I refuse to have a 'flash player' on my computer).
Interestingly www.yasiv.com once offered a '/facebook' option, but 4 years ago Facebook 'deprecated' the programming interface. On the other hand Andrei Kashcha still has his graphing software for Amazon books and YouTube videos. These are really useful, for Amazon the images below link together 224 books related to the term 'facebook'.

Below www.yasiv.com also has a YouTube application which provides a graph where each connection means that according to YouTube the video's were related.
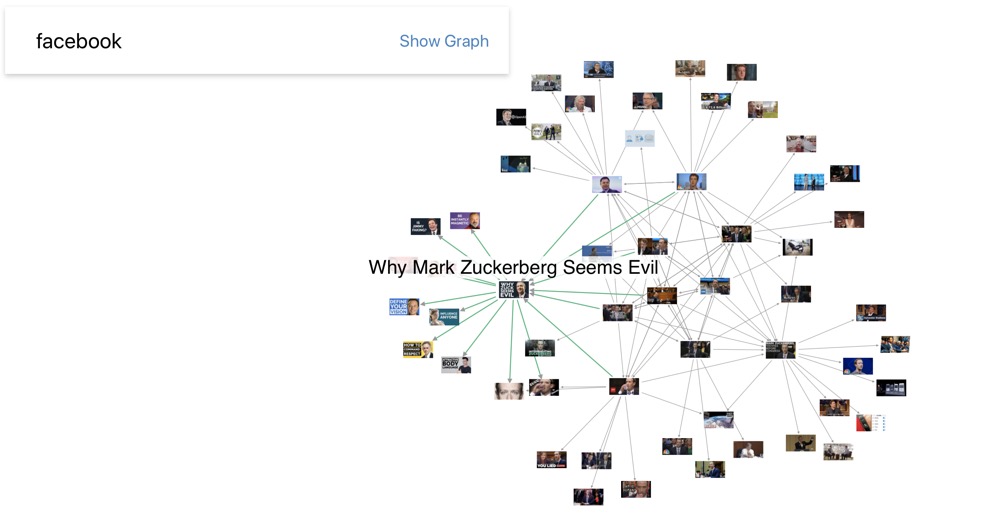
Along with tools that create visualisations of ‘social graphs’ there are also ‘scrapers’, i.e. programs that can access and collect all sorts of data held in Twitter, Facebook, etc., and store the data in text or spreadsheet files for further analysis. Facepager is made for fetching public available data from Facebook, Twitter and other JSON-based APIs. All data is stored in a SQLite database and may be exported to a CSV file. This is a basic guide and this is its Facebook page. There are a couple of useful videos, here and here.
My impression is that Facebook will look to increasingly funnel (and authenticate) developers through their facebook for developers, which provides a vast range of tools and analytics. As a developer they can register and manage the login of their users, use Messenger to 'engage' with them, use webhooks to keep up to date on how they are making changes to their own Facebook settings, etc., and (naturally) accept in-app payments through Facebook's secure payment system. Developers can exploit the Facebook Instant Gaming platform, their API Center, the Instagram API, and the Facebook Marketing API. And when everything is working they can use Facebook Analytics to better service their users, measure ad performance, and build new 'audiences' for ad targeting.
It is certainly far more intuitive for someone looking for a product or service to use Google, Amazon or eBay. Facebook is an entirely different proposition. People don't go to Facebook to buy something or to research a particular service. It all starts with a supplier who already has a functional website up and running, offering and selling products and/or services, and already able to customise engaging content for different new audiences. What Facebook offers is a way to target (or re-target) those niche audiences and to funnel them through to specific parts of the website. Everything starts with the 'warm audience'. They already know the product or service, they are on customer lists, have already visited the website, and are Facebook fans. They are a kind of baseline experiment for promotions, providing data on what's performing best. With the knowledge of the existing audience segments (those who are the most engaged and who make the most purchases), Facebook will target lookalike audiences, and again the key is to collect data from these 'cold audiences'. It is vital that the existing website is able to customise an attractive offer for new niche audiences. If true, it can be marketed to Facebook Groups and Facebook Pages. It is pointless funnelling through interested users from Facebook if the website does not deliver.
Now Facebook comes into it own. Facebook can be instructed to show a particular landing-page ad to all those people who looked at a particular blog post, but who had not visited the website of the product or service. Remember the ad takes the people to a part of the website with a customised offer. Facebook can be instructed to run a different ad (say for a discount or free trial) for all those people who visited the landing-page but who did not 'convert'. Facebook can also be configured to show an ad with trust-building testimonials to all those people who refused the discount or special offer. Facebook can also be configure with a 'hard-sell' ad just for those people who took up the special offer but still did not 'convert'.
For those reader who are into marketing jargon, what the website of a product or service does is to focus on a brands existing 'touchpoints' that shape the customer's perception of the brand. The 'touchpoints' can be almost anything - product specification and range, pricing, packaging, branding, website, cross-sell, up-sell, customer service, billing, manuals and instructions, events, newsletters, surveys, loyalty programs, promotions, gifts, testimonies, customer blog, trade shows, technologies, environmental considerations, legal issues such as privacy, regulatory requirements, safety, on-line support, training, delivery, cost of ownership, etc. Again the importance is that Facebook is used to funnel new niche audiences into an existing (and hopefully efficient and successful) web-based marketing and sales machine. And more importantly still the whole Facebook funnel is automated.
Facebook and social science research
Much of the story about Cambridge Analytica and Facebook depends upon extracting data sets to support social science research. Over the years researchers focussed on Twitter more so than on Facebook. Fundamentally Twitter is just easier to understand and use. Tweets are a simple primary unit of Twitter, whereas Facebook has no single message primary unit. Because Facebook is designed from the bottom up to scale it is both conceptually and technically complicated and highly granular. And in the past Facebook was well known for it poorly documented privacy setting, making it difficult for researchers to known what they could and could not access and use. Even the Facebook Graph API was poorly documented, and known to be unreliable for large or complex requests. Those researchers who had accessed Twitter in the past found Facebook complicated and difficult to navigate (have a look here for a paper from 2013 telling us that Twitter was the Drosophila of social media research). For example, in the Facebook social graph nodes can be users or pages, and can have different fields and edges. What should a researcher collect, and what other connected nodes should be collected as well? Collect everything, you say. But be careful. As an example, retrieving a page on a famous person with their many associated photographs, videos, posts, comments, etc. actually took nearly 50 hours (2018 time), when including their friends profiles as well. The problem is that the request process is complex. An optimised request for the same information later took ‘only’ 87 minutes. It is true that a request to download and backup a user profile usually only takes a few minutes, but that does not include downloading the profiles of all their friends or the history of their extended comments and discussions, etc. Even in the past quite a lot of data would normally be private, although a lot of other information is public (e.g. comments) and can also contain sensitive information. In the case of Cambridge Analytica and Facebook it would appear that Cambridge Analytica were allowed access to a lot of private data, and that Facebook either ‘turned a blind eye’ or that their privacy rules were not enforced or were easy to circumvent. Give the lack of clarity of Facebook’s rules at the time it would appear that they allowed third-party apps to collect data about Facebook user’s friends, but this has changed now. It looks like they simply did not enforce their rules, and that meant that Cambridge Analytica just went ahead and used the data they had scraped from Facebook for non-academic purposes. Naturally all parties have expressed differing and contradictory opinions on what happened.
This will be short, but I would like to log a plea for the use and collection of social science data. Archives are a necessary social institution, some are national, others of film, some institutional, and some collect social science data (e.g. the UK Data Archives). Archives contain primary source documents that are presumed to be of enduring cultural, historical, or evidentiary value. Web archiving is essentially the same in that portions of the World Wide Web are preserved for researchers, historians, and the public.
The social sciences must collect a massive amount of data from social surveys through to health statistics and market research data. A lot of data is collected using public funds (e.g. environmental research, space science,…), and data archival is mandatory. Other types of digital data on such things as drug development or construction projects must also be archived for regulatory and insurance purposes. Would anyone be able to understand the details of the Trump presidency without an archive of his Twitter account? But this is not just about ‘data stewardship’, curation and ‘digital preservation’ of the past, since the analysis of this data also helps in the formulation of future public policies. For example, Twitter data has been used to predict riots, and Facebook has been use to understand eating disorders in adolescent girls, and how it enhances and undermines psychosocial constructs related to well-being.
I just hope that the fallout from the Cambridge Analytica and Facebook affair does not adversely affect the archival and use of data necessary to the social sciences.
Facebook news services (fake or otherwise)
Facebook Watch was launched in 2017 as a video-on-demand service. In part they wanted to compete with the video sharing platforms YouTube and Snap, in part they were looking to own and control original content, and in part they wanted to manage better the quality of news content being shared on their platform. No matter how you look at it, initially this was all about monetisation with Facebook sharing advertising revenues. In fact Facebook continued to say that people come to them to ‘see’ friends and family, not news. But the reality is that family and friends increasingly share news items. In 2017 Facebook admitted that they did not think that the way they focussed on dealing with the problems of ‘fake news’ and news integrity was time well spent. They were looking for new ways to confront ‘head on’ fake news and content that “violated community standards”. Now in 2018 their approach has changed again, and after again stressing that they are not a media company, their algorithms will now prioritise personal moments shared between friends and family, and focus less on news as a service. Facebook claimed in 2016 that they could squat fake news but where is the proof? In any case the changes they have made to Watch might be just a way to turn their back on the fake news problem, but it is also a more frontal attack on the YouTube market. The new Facebook Watch revenue model is now similar to that of YouTube, where content creators can upload their content free, and earn a cut in the revenue from ads placed on that content. Here is an interesting timeline of the history of Facebook’s Newsfeed algorithm.
Facebook has also recently upgraded its ‘info’ icon button, which provides more information about an article and the publisher, and users will be able to see which of their ‘friends’ shared fake news so they can ‘unfollow’ them. Most experts think that this is not going to be enough. The reality is that social networks live off advertising. They create ‘like-minded’ groups, aggregate user attention, and then sell that on to advertisers. Those who create fake news and want to propagate disinformation want to manipulate the behaviour of like-minded groups. So their objectives are subtly and unwittingly aligned.
Disinformation is not what you think
It would be a mistake to think that disinformation campaigns are limited to shovelling fake content onto Facebook, Google or Twitter. Digital advertising and marketing exploits precision online advertising, social media bots, viral memes, search engine optimisation, and intelligent message generation for different micro-targets. Modern day advertisers use these techniques, and disinformation operators are replicating all the same techniques. The interests of social media networks and advertisers are aligned, but the problem is that disinformation operators are typically indistinguishable from any other advertiser. Social networks capture every click, purchase, post and geo-location. They aggregate the data, connect it to individual email addresses or phone numbers, build consumer profiles, and define target audiences. Precision advertising is a kind of in-vivo experiment. Target audiences are not static, and the modern advertiser is looking to drive sentiment change and persuade users to alter their perception of a given product or service. Systems allow a kind of automated experimentation with thousands of message variations paired with profiled audience segments (and across different media channels). Advertisers also look to optimise search engine results and employ people who spend their time reverse engineering Google’s page rank algorithm. All the tracking data, segmentation, targeting and testing, and measures of relative success and failure are grit for machine learning algorithms. Disinformation operators want the same thing, precise audience targeting for their message. The way precision advertising can drive popular messages into becoming viral phenomenon is also exactly what a disinformation operator wants as well. They also want to see their messages on the top of Google’s search pages. But there is a key difference. Google can usually detect something is not right, and within hours they can correct for any distortions. But if it happens just before an election and the message goes viral, a few hours could be too late.
This webpage is all about Cambridge Analytica and Facebook, and how user data from Facebook was used to profile and target specific ‘like-minded’ groups. But we must not forget that the other side of the coin is the content, fake or misleading, which is used to ill-inform or disinform. The key is to coordinate lots of information, made quickly, made together, and all selling the same message.
Alexa, and Amazon company, provides a set of analytic tools, including providing traffic estimates for specific websites. So why can one lowly ranked site come out on top of a Google search?
You start with a strong message, and be sure to put solid honest caveats in the footnotes, e.g. “no evidence yet…”, “yet to be proven”, “no evidence made available yet”. You often see “… they had not replied by the time of publication”, and “… did not respond to a request for comments”. True or not, this kind of caveat is often used in the mainstream media and even by good journalists, and gives a sense of investigative credibility to any text.
Some sources simply invent stupid stories, but even these stories have their role to play because they give credence to other stories that subtly masks or distorts the truth.
Texts are written in a way that are easy to read and above all compelling to share. To get people to share, authors flatter their readers and make them look well informed and smart, using ’new’, ‘recent’, etc. so that they want to get in first and share. Authors use popular language and re-use words and expressions used by the more mainstream media, even if they may define the terms differently. Again the key is to create an alternative narrative. Authors use keywords that are used by their target audience, i.e. they may love words like evidence, Trump, Russia, CIA, new, secret, proof, …, and authors will always write in a way that allows them to rapidly re-use the same texts and references in the future, thus creating consistency over time (backward consistency creates a sense of credibility). Synchronising content around those key words will help search engines pick up on them. The same basic message must be cut-and-pasted into multiple articles over dozens of websites, all at the same time. Authors will cross-reference their different websites together, using each as a reference for the other. And they try to make sure each of their websites is referenced abundantly by many other websites (that is why they have a lot of websites up and running on a whole variety of topics, so they can reference each other). Also authors will abundantly reference mainstream media, even if it is simply to say that they are just part of a corrupt government-business conspiracy. Authors must try to build conversations, and foster lots of comments, positive and negative (even if they have to write them themselves under pseudonyms). Now all they need to do is beam out their information to their micro-targeted demographics. That means publishing, and then updating and re-publishing, and re-writing, and tweaking, all because Google’s algorithms like newness. Even if the original news items are one week old, everything is written as if it is a breaking story.
And perhaps the most important things is that this type of disinformation is not targeting an opponent or adversary, it is designed to further attract, entrench or indoctrinate supporters (micro-targeted users, ‘like-minded’ communities, the tribe).
Check out this report by TIME and this by The Guardian, for a really good insight into the work of misinformation.
If you want to know what Facebook thinks of “actions to distort domestic of foreign political sentiment” have a look at their 2017 report Information Operations and Facebook.
Here we have an article on “Analysing the Digital Traces of Political Manipulation: The 2016 Russian Interference Twitter Campaign”, and the Harvard report on the 2016 US Presidential elections entitled “Partisanship, Propaganda, & Disinformation”.
Other authors look at the ‘larger picture’ with the 2016 report “Who Controls the Public Sphere in an Era of Algorithms?”, the 2017 White Paper “The Fake New Machine”, and the 2017 reports on “Computational Propaganda” and “Troops, Troops and Troublemakers: A Global Inventory of Organised Social Media Manipulation”.
Have a look at the recent and very extensive 2018 article “Media Manipulation 2.0: The Impact of Scale Media on News, Competition and Accuracy”, and the very recent (March 2018) opinion of the European Data Protection Supervisor on online manipulation and personal data.
If your are looking for a more technical perspective, try reading these articles, “The Ethics of Automated Behavioural Microtargeting, “Can We Trust Social Media Data? Social Network Manipulation by an IoT Botnet”, “The State of Fakery” and “On Cyber-Enabled Information/Influence Warfare and Manipulation”.
No matter how you look at it identifying ‘fake news’ is difficult
We must be honest with ourselves, identifying fake news is a challenge. The Gartner Group recently predicted that by 2022 the majority of people in advanced economies will see more false than true information. In fact there is something called The Fake News Challenge run by volunteers in the artificial intelligence community. The first challenge was simply to identify whether two or more articles were on the same topic, and if they were, whether they agreed, disagreed, or just discussed it. Talos Intelligence, a cybersecurity division of Cisco, won the 2017 challenge with an algorithm that got more than 80% correct. The top three teams used deep learning techniques to parse and translate the texts. Not quite ready for prime time, but still an encouraging result. The reality is that given the limitations in language understanding these techniques are likely to be used as tools to help people track fake news faster. Future challenges will look at more complex tasks such as images with overlay fake news texts. This technique has recently been introduced by sites that harvest ad dollars after new controls were introduced by Google and Facebook.
But will it be enough? You can try to identify, label and choke off fake news suppliers, but nothing is done about those who consume fake news. The same Gartner report predicted that growth in fake content will continue to outpace artificial intelligences ability to detect it.
Yet the ongoing premise is that humans will not be able to detect and disarm today’s weaponised disinformation, so we need to look to machines to save us. Individuals might not worry too much about the truth of some stories, we have a multitude of ways to filter out fake news and a multitude of ways to want to believe in what fake news is telling us. But content platforms and advertisers may have something to lose by hosting or being associated with fake news. They can try to cut off revenue streams for those who create fake news, but they need some automated tools (Trive might be one way forward). These tools can start to identify phoney stories, nudity, malware, and telltale inconsistencies between titles and texts. Sites can be blacklisted, image manipulation identified, and texts checked against databases of legitimate and fake stories. One problem is that machine learning techniques are also being use to create ever-more convincing fakes. The smartphone app called FaceApp can automatically modify someone’s face to add a smile, add or subtract years, or even swap gender. It can smooth out wrinkles, and even lighten skin tones. Lyrebird can be used to impersonate another person’s voice. In 2016 Face2Face demonstrated a face-swapping program. It could manipulate video footage so that a person’s facial expressions matched those of someone being tracked using a depth-sensing camera. Different but related to this, another research project showed how to create a photo-realistic video of Barack Obama speaking a different text (right down to convincing lip sync and jaw/muscle movement). It is early days, but these types of technologies go beyond just fake news issues and actually challenge the meaning of juridical evidence.
Some experts tell us not to overreact. One study showed that fake news during the 2016 Presidential elections was widely shared and heavily tilted in favour of Donald Trump. Whilst more than 60% of US adults got news from social media, only 14% of them viewed that media as their most important source of election news. At the end of the day the study concluded that the average US adult saw and remembered just over one fake news story in the months before the election, and that the impact on vote shares was probably less than 0.1%, i.e. smaller than Trump’s margin of victory in the pivotal states.
The Tide Pod Challenge
Eliminating fake news is a challenge. How do you stop fake news from spreading and mutating, from jumping from one platform to another, given that what makes an idea outrageous and offensive is what makes it go viral in the first place? As early as 1997 kids were playing the competitive milk chugging challenge, i.e. to drink one US gallon (3.8 litres) of whole milk in 60 minutes without vomiting. Then in 2001 there was the cinnamon challenge, i.e. eat a spoonful of ground cinnamon in under 60 seconds without drinking anything. And upload the video to YouTube. These challenges carry substantial health risks. Salt and ice is another challenge, as is the Banana Sprite challenge.
In 2015 The Onion, a US satirical newspaper, published “So Help Me God, I’m Going to Eat One of Those Multicoloured Detergent Pods” from the perspective of a strong-will small child. The reality is that children do eat brightly-coloured sanitisers, deodorants, and detergent pods. After that people who should know better started to eat the pods. In early 2018 the “Tide Pod Challenge” swept across the Internet. People posted YouTube videos of themselves eating Tide Pods and videos of those challenged to eat one (it is both disgusting and toxic).
In the spirit of fake news we must ask at what point should YouTube and Facebook start taking down Tide Pod content? Some videos warn people not to eat Tide Pods, others are awash with irony, yet others are jokes and present juicy Tide Pod pizza. Yet other videos actually show people eating the Tide Pods. How to provide moderation guidelines, or program automated filtering software? And we should never forget that taking down videos can actually draw more attention to them (Streisand effect).
You ‘solved’ the Tide Pod problem, and now comes Peppa Pig drinking bleach. Stuff like this is neither innocent, nor knee-jerk repulsive. It can easily attract some apparent interest, which can as easily get amplified. If the recommender systems ‘think’ people are interested, then other people will start automatically to remix new pieces of content. It is spam, but no longer is it designed to sell you something. Your attention is the new commodity. Your attention is sold back to the social media platform’s ad engine and someone else has to try and see how to make money on Peppa Pig going to the dentist.
You think that all this is just fantasies on the Internet? As an exercise have a look at Pizzagate, which connected several US restaurants with high-ranking officials of the Democratic Party, and an alleged child-sex ring. In June 2017 Edgar Welch was sentenced to 4 years for firing an assault rifle in D.C.’s Comet Ping Pong pizza restaurant after he had watched hours of Youtube videos about Pizzagate. He said he was convinced that the restaurant was harbouring child sex slaves. Fortunately no one was hurt.
As with any complex, dynamically changing and partially 'intransparent' technology some unanticipated consequences are inevitable, and some even may be desirable. The Internet, social networks, and even advertising are not in themselves perverse technologies, but ignorance and mistaken hypotheses can create situations which are unacceptable to society. Ignorance we can (must) address by increasing our understanding of both the technology and its inherent characteristics. Given that unanticipated consequences are inevitable in all activities, our objective must be to try to reduce both short-term and long-term uncertainty (but that will always have a cost). We may want to slowdown technological progress, or hold things up whilst we carry out further studies, analysis, and experiments. We may think that any long-term ‘solution’ will cost too much time and money, so we aim for short-term ‘quick fixes’. But those quick fixes could cost more in the long run. For example we know fake news devalues and delegitimises expertise, authoritative institutions, and the concept of objective data. The long-term consequence could be that society’s ability to engage in rational discourse based upon shared facts in undermined. We can look to take out some kind of ‘insurance’ by bring an industrial sector together to cover the catastrophic consequences of their collective actions. This could include self-regulation with ‘disputed’ and ‘rated false’ warning banners, possibly inserted by a new type of independent, trusted gatekeeper. We can look to control, regulate or guide an industrial sector. We can legislate against certain practices. This will have financial consequences and will also reduce their/our freedoms. Or should we look at fake news as a symptom of much deeper structural problems in our media environment? Perhaps we have to accept that popularity, engagement, and ‘likes' and ‘shares’ are now more important that expertise and accuracy.
US indictment of Russians 2018
In March 2018 we had the US announcing criminal charges against Russians who interfered in the 2016 elections, and Facebook telling us that the Russians abused their system. The indictment mentions 41 times the use of Twitter, Youtube and Facebook to “divide America by using our institutions, like free speech and social media”. At one level the idea is to cause confusion, distrust, and sow division, but equally it is stated in the indictment that the Russian Internet Research Agency (also known as the Trolls from Olgino, one of Russia's Web Brigade) employed a dozen full-time staff and spent $1 million a month to try to ensure that Clinton was not elected. A particular feature of this interference was their targeting of minority groups to encourage them to stay away from the polls, on the basis that neither Clinton nor Trump were worth it.
This article includes the video of the indictment, and naturally many people have pointed out that the US is no stranger to doing the same. Time has pointed out that the Russians are also targeting the US 2018 election cycle. Time has also noted that Russian intrusions in to the 2016 US elections was more extensive than originally reported.
The problem today is that the misuse of social networks may be banned as a matter of policy, but social networks are actually designed to share freely and openly peoples ideas, comments and opinions, and to do so rapidly and globally. Ads could be used to target people, for example asking them to follow a Facebook page on Jesus. Later they would use that group to spread the meme of Hillary Clinton with devil horns. Facebook itself estimated that 10 million people saw that paid ad, but that 150 million people saw the meme generated from fake accounts. During the 2016 elections the six most popular Facebook pages of the Russian Internet Research Agency received 340 million ‘shares’ and nearly 20 million comments, etc. The reality is that Facebook algorithms supported and aggressively marketed the micro-targeting used by the Russians because they are designed to focus on and support very active social and political discussion, divisive or otherwise.
According to a Wired article the Russians did not abuse Facebook, they simply used it in the way it was designed to be used.
Others have echoed this analysis. Social networks such as Facebook are designed to promote certain types of content. An idea that can motivate people to share it will always thrive and spread (it is the definition of viral content). Content creators optimise their content for sharing, and social networks optimise for advertising revenue. Social networks are easy to access and sharing content is almost instantaneous and on a global scale. On top of all that the social networks try to personalise content, meaning that whatever is good or bad gets into the hands of people who are most likely to find it appealing and worth sharing. So the underlying structure of social networks implies that they will forever go from one crisis to another. Removing one type of unacceptable content due to one crisis, will just be followed by the next content-crisis. Russian content trolls were not the first ‘baddies', and won’t be the last.
So who exactly is Cambridge Analytica?
According to their own website Cambridge Analytica “use data to change audience behaviour”, and they have two divisions: Commercial (data-driven marketing) and Political (data-drive campaigns). Their core skills are market research, data integration, audience segmentation, targeted advertising and evaluation. Wikipedia tells us that Cambridge Analytica belongs to the SCL Group which is partly owned by Robert Mercer. Mercer is a US-born ex-computer scientist, the co-founder and now ex-CEO of the hedge fund Renaissance Technologies, and part-owner of the US-based far-right Breitbart News. Wikipedia tells us that Mercer was (and probably still is) one of the most influential billionaires in US politics. He is known to have supported US Republican political campaigns, the Brexit campaign in the UK, and the recent Trump campaign for the US presidency.
What did Cambridge Analytica do wrong?
In simple terms they are accused of collecting and exploiting Facebook user data from about 50 million people without getting their permission. According to this article in 2014 Cambridge Analytica promised Robert Mercer and Stephen K.Bannon (responsible for making Breitbart News a platform for the alt-right) to “identify the personalities of American voters and influence their behaviour”. To do this they harvested personal data from Facebook profiles for more than 50 million Americans without their permission. This ‘data leak’ allowed Cambridge Analytica to exploit the private social media activity of a huge group of the American electorate, developing techniques that underpinned their work on Trump’s US presidential campaign in 2016.
When did it all start?
According to the mainstream press (the ‘simple' story) it is supposed to have all started in 2014 with the Amazon mechanical turk. This is a marketplace that brings clients and workers together for a range of data processing, analysis, and content moderation tasks (it takes its name from a late-18th C fake chess-playing Turk machine). The story goes that a task was posted by “Global Science Research” offering ‘turkers’ $1 or $2 to complete an online survey. But they were only interested in American ‘turkers’ and they had to download a Facebook app which would “download some information about you and your network … basic demographics and likes of categories, places, famous people, etc. from you and your friends”. This request was suspended in 2015 as a violation of Amazon’s terms of service. In fact some of the ‘turkers’ noticed that the app took advantage of Facebook’s ‘porousness’ by collecting everything that they wrote or posted with their friends. It is claimed in several reports that Facebook provided tools that allowed researchers to mine the profiles of millions of users. At least until 2014 Facebook allowed third-party access to friends’ data through a developer's application, a kind of back-door to the Facebook social graph. New privacy setting were introduced, but some reports clearly suggest that Facebook continued to encourage third-party data ‘scraping’. It is true that Facebook later asked Dr. Kogan and Cambridge Analytica to delete the data they had collected. The problem was that Facebook did not police how their data was collected and used by third-parties, and did not check to see if their rules were being respected.
Why did Global Science Research want to collect all this data?
Firstly, they were a UK-based company doing market research and public opinion polling. Incorporated in 2014, it was voluntarily dissolved in October 2017. The company founders were a US citizen called Dr. Aleksandr Spectre and another US citizen Joseph Andrew Chancellor. Chancellor was a post-doctoral researcher in the University of Cambridge, and is now a quantitative social psychologist on the User Experience Research team of Facebook.
In fact as far as I can tell two companies were created and later dissolved. One called Global Science Research registered in 29 Harley Street, London (an off-shore address for more than 2,000 companies), and the other Global Science (UK) registered at Magdalene College in the University of Cambridge.
Spectre was 'temporally' the name of Dr. Aleksandr Kogan. In 2015 he married a Singaporean named Crystal Ying Chia and together they changed their family name to Spectre (they divorced in 2017). There is ample evidence to show that they picked Spectre as a derivative of Spectrum, since they were married in the international year of light (so forget all those Jame Bond references). Another source noted that he has now changed his name back again to Kogan. However, at this moment in time Dr. Aleksandr Spectre is registered as a research associate in the Department of Psychology in the University of Cambridge. His research interests are in prosocial emotional processes, and in particular the biology of prosociality, close relationships and love, and positive emotions and well-being. He is also mentioned as being a member of the Behavioural and Clinical Neuroscience Institute, part of the Department of Psychology. He has a separate blog on Tumblr where he mentions his research interests in well-being and kindness. He also mentions being the founder/CEO of Philometrics, a survey company that claims to be able to automatically take a survey with 1,000 responses and forecast how another 100,000 people would answer the same survey.
Also at this moment in time Dr. Aleksandr Kogan has a separate page under Neuroscience in the University of Cambridge (also in the Department of Psychology). He also appears on a different page for Cambridge Big Data.
There are numerous sources telling us that Dr. Aleksandr Kogan worked for Cambridge Analytica. They say that he harvested personal data from millions of Facebook users and passed that information on (I presume to Cambridge Analytica). They state that much of the information was obtained without users consent. It is also said that Cambridge Analytica created psychological and political profiles of millions of American voters, so that they could be targeted as part of the Trump 2016 presidential campaign. Facebook has suspended SCL Group, Cambridge Analytica, and Dr. Kogan. There is a privacy class-action lawsuit open against Cambridge Analytica and Facebook, and Facebook (and Zuckerberg) is being sued by shareholders in separate class-action lawsuits claiming that executives and board directors failed to stop the data breach or tell users about it when it happened, thus violating their fiduciary duty.
However, the University of Cambridge has made a written statement about Dr. Aleksandr Kogan and his work in the Cambridge Prosociality and Well-Being Lab (in fact he is the lab’s director). It confirms that he owned Global Science Research and that one of his clients was SCL, the parent of Cambridge Analytica. It states that none of the data he collected for his academic research was used with commercial companies. The situation appears to have been that he developed a Facebook app for collecting data for academic research. But that the app was repurposed, rebranded and released with new terms and conditions by Global Science Research. It also mentions that Dr. Kogan also undertook private work for the St. Petersburg University in Russia.
The Mail Online from the 3 April 2018 questions this simplistic view. They noted that some of Dr. Kogan’s colleagues disapproved of his research, and that the situation was not as clear-cut as suggested in the above written statement. It would appear that Cambridge Analytica paid Global Science Research £570,000 to develop a personality survey called This Is Your Digital Life. They paid between £2.10 and £2.80 to each of 270,000 US voters to complete the survey via a Facebook app. This part of the story appears to overlap with the payment made to ’turkers’. Different reports suggest that the original idea was to create an app called ‘thisisyourdigitallife’ that offered Facebook users personality predictions, in exchange for accessing their personal data on the social network along with some limited information about their friends, including their ‘likes’. In any case the app did harvest information from Facebook profiles of those users friends’, meaning that data on more than 30 million people was collected (this figure was upgraded to 50 million in numerous articles, and most recently upgrade again to 87 million). The Mail Online noted that Dr. Kogan thought that he was acting perfectly appropriately and now was being used as a scapegoat by both Facebook and Cambridge Analytica. In addition he thinks that the data collected was not that useful, and that Cambridge Analytica was exaggerating the accuracy and trying to sell ‘magic’. It must be said that other psychologists in the University of Cambridge are of a different opinion. They claim that findings show that accurate personal attributes can be inferred from nothing more than Facebook ‘likes’.
Reports and articles differ in the details
Some news reports suggest that Dr. Kogan and Global Science Research were paid by Cambridge Analytica to collected the data on millions of people. Other reports suggest that the original app was modified and then used by Cambridge Analytica to collect that same data. Yet other reports say that the original app was created as a research tool, but then transferred to Global Science Research. There it was renamed and the terms and conditions changed before being used by Cambridge Analytica. Cambridge Analytica is on record as saying that it did not use Facebook data in providing services to the 2016 Trump presidential campaign. Global Science Research is on record as saying that the users of the Facebook app were fully informed about the broad scope of the rights granted for selling and licensing, and that Facebook itself raised no concerns about the changes made to the app. The whistleblower Christopher Wylie (more about him later) suggests that Facebook did most of the sharing and they were perfectly happy when academics downloaded enormous amounts of data.
An article in The Guardian states that Dr. Kogan and Facebook were sufficiently ‘close’ that Facebook provided him in 2013 with an anonymised, aggregated dataset of 57 billion Facebook friendships, i.e. all friendships created in 2011. The results on the "wealth and diversity of friendships” were published in 2015.
Deep Root Analytics
For a moment we are going to turn away from Cambridge Analytica and Facebook, but we are not finished.
Deep Root Analytics looks at media consumption and offers TV targeting technology, i.e. helps companies make better ad buying decisions. The company was founded in 2013 by Sara Taylor Fagen (former aide to George W. Bush), Alex Lundry (a data scientist and micro-targeter) and TargetPoint Consulting. TargetPoint Consulting was founded in 2003 by Alexander P. Gage, creator of political micro-targeting. TargetPoint were exclusive data suppliers to the Bush-Cheney ’04 campaign. Deep Root Analytics was to improve micro-targeting for web-enabled media. In June 2017 Deep Root’s political data for more than 198 million American citizens (ca. 60% of the US population) was found on an insecure Amazon cloud server. At the time they were working for the US Republican National Committee on a $983,000 contract. The data was a compilation and included information from a variety of sources, including from The Data Trust, the Republican party’s primary voter file provider. Data Trust received $6.7 million from the Republican Party in 2016, and its president is now Trump’s director of personnel. Other contributors have been identified as i360, The Kantar Group, and American Crossroads. The 1.1 terabytes of data included names, addresses, dates of birth, voter ID, browser histories, sentiment analysis and political inclination, etc., but not social security numbers. It also included peoples suspected religious affiliation and ethnicity, as well as any positions they might have on gun ownership, stem cell research, eco-friendliness, the right of abortion, and likely (predictive) positions on such things as taxes, Trump's “America First” stance, and the value of Big Pharma and the US oil and gas industry. It must be said that much of the data originally was used to understand better local TV viewership for political ad buyers. All modern-day political organisations collect bulk voter data to feed their voter models. TragetPoint, Causeway Solutions and The Data Trust worked for the Republican Party, but other companies such as NationBuilder and Blue Lab work for the Democrats. Some of the data such as voter rolls are publicly available, other data was created by proprietary software. In fact Obama’s 2012 campaign also collected information from Facebook profiles and matched the profiles to voter records. The key problem is that Deep Root Analytics failed to protect the data. It must be said that the data left on the server was mostly from 2008 and 2012, and even today the 2016 data is considered by experts as ’stale’. A class-action lawsuit has been filed against Deep Root Analytics.
Back to Cambridge Analytica and Facebook
Earlier on I wrote that it all started in 2014 with the Amazon mechanical turk. But I also noted that some of Dr. Kogan’s colleagues disapproved of his research. In fact this story goes back further than 2014.
In 2013 Michal Kosinski, also with the University of Cambridge, published a paper entitled “Private Traits and Attributes are Predictable from Digital Records of Human Behaviour”. The focus was on using Facebook ‘likes’ to automatically and accurately predict a range of highly sensitive personal attributes including: sexual orientation, ethnicity, religious and political views, personality traits, intelligence, happiness, use of addictive substances, parental separation, age, and gender. The information was collected through the voluntary participation of Facebook users by offering them the results of a personality quiz MyPersonality. The basic idea was that the app enabled users to fill out different psychometric questionnaires, including a handful of psychological questions such as “I panic easily” or “I contradict others". Based on the evaluation, users received a “personality profile” (individual Big Five values - see below on psychometrics) and could opt-in to share their Facebook profile data with the researchers. Firstly the research team was surprised by the number of people who took the test. Secondly they tied the results together with other data available from Facebook such as gender, age, place of residence, ‘likes’, etc. From this they were able to make some reliable deductions, such as one of the best indicators for heterosexuality was ‘liking’ Wu-tang Clan, a US hip-hop group. People who followed Lady Gaga were likely to be extroverts, and introverts tended to like philosophy. Each piece was too weak to provide any reliable prediction, but thousands of individual data points combined to allow some accurate predictions. By 2012 Dr. Kosinski and his team, based upon 68 Facebook ‘likes’, was able to predict skin colour (95% accuracy), sexual orientation (88%) and affiliation to the Democratic or Republican Party (85%). With lower accuracy they also tried to predict alcohol, cigarette and drug use, as well as religious affiliation, etc. They later claimed that 70 ‘likes’ were enough to outdo what a person’s friends knew, 150 what their parents knew, and 300 what their partner knew.
It is said that on the day that Dr. Kosinski published these findings, he received two phone calls. The threat of a lawsuit and a job offer. Both from Facebook.
Dr. Kosinski is now an associate professor at Stanford Graduate School of Business. As a quick follow-on, Facebook ‘likes’ became private by default, but many apps and online quizzes ask for consent to access a Facebook users private data as a precondition. Dr. Kosinski is quoted as saying that using a smartphone is like permanently filling out a psychological questionnaire. Every little data point helps, i.e. the number and type of profile pictures, how often users change them (or not), the number of contacts, frequency and duration of calls, etc. Even the motion sensor in a smartphone can reveal how quickly we move, and how far we travel (signs of emotional instability). Once the data collected, it can be ‘people searched’ to identify angry introverts, or undecided Democrats, or anxious fathers…
Dr. Kosinski has his own website where he points to the myPersonality Project, the Concerto adaptive testing platform, and the Apply Magic Sauce personalisation engine.
The Psychometrics Centre of the University of Cambridge has a whole page of psychological profile tests, ranging from MyPersonality 100 to MyIQ through FaceIQ and 2D Spatial Reasoning.
The other two authors of the Dr. Kosinski's 2013 paper were David Stillwell and Thore Graepel. Stillwell worked with Kosinski in Cambridge and is now deputy director of the Psychometrics Centre and lecturer in big data analytics and quantitive social sciences (see his 2017 video). Graepel worked in Microsoft Research in Cambridge, and is now Professor of Machine Learning at UCL and research lead at Google’s DeepMind (you can check out his work here as of 2012 in Microsoft Research). A number of Freedom of Information requests have been made to the University of Cambridge to get access to the research results. It would appear that the position of the university is that all the data belongs to Kosinski or Microsoft Research, or both.
It is said that Dr. Kogan wanted to commercialise Dr. Kosinski’s results, but he declined. Dr. Kosinski has also said that Dr. Kogan tried to buy myPersonality on behalf of a deep-pocketed company, SCL. After that Dr. Kogen then built a new app for his own startup Global Science Research. In 2014 data was harvested under a contract with Cambridge Analytica, and used to build a model of 50 million US Facebook users, including allegedly 5,000 data points per user. The app collected data for 270,000 facebook users, and with 185 friends per user, this represented 50 million full profiles. Of that 30 million profiles had enough information in them to allow a correlation with other real-world data held by data brokers and political campaigners. This meant that Cambridge Analytica could connect the psychometric Facebook profiles to 30 million actual voters. Facebook no longer allows such an expansive access to friends’ profiles using a simple API. It is still unclear what data was moved from the academic context to the commercial context in Cambridge Analytica, and what role Dr. Kogan play in that.
Mainstream media has not delved into the work of Michal Kosinski nor the ‘background’ between Dr. Kosinski and Dr. Kogan. My understanding is that in December 2016 Das Magazin (English translation) first took up the story in which Dr. Kosinski seemed to suggest that SCL and Cambridge Analytica might have stolen (repurposed without permission) his team’s research. It was the Canadian-based VICE’s Motherboard that published the English translation of the German article, and from that the topic went viral.
What exactly is psychometrics?
We have not specifically mentioned the word psychometrics, but the Cambridge Analytica and Facebook story is rooted in psychological testing, measurement and assessment. The aim is objective measurement of attributes such as skills and knowledge, abilities, attitudes, personality traits, and education achievement. The tools are questionnaires, tests, judgement ratings, and personality tests. The topic has quite an illustrious past with contributions from figures such as the pioneer in eugenics Sir Francis Galton and Ernst Heinrich Weber founder of experimental psychology. In the 1980’s psychologists developed the ‘Big Five’ model for assessing personality traits. These are also known as OCEAN: openness (how open you are to new experiences?), conscientiousness (how much of a perfectionist are you?), extraversion (how sociable are you?), agreeableness (how considerate and cooperative you are?), and neuroticism (are you easily upset?).
The "Big Five" has become the standard technique of psychometrics. But for a long time, the problem with this approach was data collection, because it involved filling out a complicated, highly personal questionnaire. Then came the Internet. And Facebook. And practitioners such as Kosinski.
The Cambridge Analytica and Facebook story is not a simple one. Do we think that Dr. Kogan is some kind of Machiavellian mastermind, or simply a thief of the work of Dr. Kosinski, or is he being used by the University of Cambridge and Cambridge Analytica as a scapegoat?
Setting the early context to Cambridge Analytica
Enter a third perspective, or rather an even more detailed review of the story. Here we go back even further to try to understand the context in which Cambridge Analytica worked.
In 1989 Nigel Oakes established the Behavioural Dynamics Working Group in UCL. In 1990 he was involved with the creation of the Behavioural Dynamics Institute, and in 1993 he established the company Strategic Communication Laboratories (late called simply SCL). We have to realise that SCL initially provided “target audience analysis” for election management, but after 9/11 they started also to work on “counter terrorist propaganda and disinformation overseas” and later still providing training in “advanced counter-propaganda techniques”, and in particular on ways to counter Russia’s propaganda in Eastern Europe. This article suggests that SCL has been involved with more than 100 election campaigns in 32 countries, and was charging each anything between $200,000 and $2 million. If this other article is to be believed SGL/Cambridge Analytica had and still has links with UK ex-military specialists, Conservative MP’s and party funders, as well as ex-Ministers from past UK governments (Eton old boys is often mentioned).
There are reports that mention that the methodology of the Behavioural Dynamics Institute was the most advanced way to measure populations and determine, to a high degree of accuracy, how population groups may respond under certain conditions. Apparently the methodology was the only one of its type and had been verified and validated by both the US and UK defence communities. You can check out their videos on Vimeo. This view of their uniqueness is probably highly optimistic, however they were successful in selling the idea to look at social groups rather than individuals and to not focus on trying to make people change their minds. The key was to ask the right questions, and to target the undecided and their worries about local issues such as housing, water shortages, or tribal conflicts. They also charged a lot for their services, and so they tended to work for the underdog candidates who had money. Much later in 2013 when they started to look to the US, they only focussed on Republican donors, i.e. the underdogs with money. It was Christopher Wylie who, with his knowledge of social media platforms and big data, transformed SCL’s election management offer (more on the whistleblower Christopher Wylie later). This enables SCL to really target the US market, to create Cambridge Analytica, and to attract a major investment from Robert Mercer, a Republican donor.
We now turn to the billionaire Robert Mercer who had originally worked in the field of natural language processing before creating a successful hedge fund. The stock-in-trade of the hedge fund is quantitative analysis and high-frequency trading. After the ‘Quant Quake’ of 2007 and the ‘Flash Crash’ of 6 May, 2010 the public were alerted to the dangers of high-frequency trading. It was Peter DeFazio, US Representative for Oregon, who suggested the idea of a financial transaction tax, a tax that would particularly hit high-volume, high-frequency trading. Strangely, his 2010 selection campaign was almost derailed by well funded ads attacking him and supporting his ‘Tea Party’ Republican opponent, Art Robinson. The ads were placed by Concerned Taxpayers of America, and part funded by Mercer to the tune of more than $600,000. In June 2011 Mercer invested $10 million to become co-owner of the ultra-conservative Breitbart News, and at the same time he promoted Stephen Bannon to the board of directors. When Andrew Breitbart died in 2012 Bannon became Executive Chairman of Breitbart News. During this period Bannon, who was a fervent supporter of the conservative US Tea Party, also became a supporter and friend of the right-wing populist party UKIP.
The article suggests that his unsuccessful attacked on DeFazio catalysed Mercer’s interest in Republican politics, and lead him in 2012 to spend $2 million creating the Government Accountability Institute with Peter Schweizer and Stephen Bannon (both associated with Breitbart News). Not surprisingly each time the ‘Institute’ published a report, etc. it was picked up and discussed by Breitbart News, and then by major media outlets. Thats the way it works!
It was also in 2012 that Mercer is said to have spent $5 million investing in Strategic Communication Laboratories (later known as SCL Group). By 2012 SGL portrayed itself as working in behavioural dynamics and strategic communications (i.e. psychological warfare). At the time they were not involved in algorithmic data processing, but today they are known for data mining and analysis on audience groups with the aim to modify their behaviour. They call this “local election management” and they claim to have been involved in “behavioural change programs in over 60 countries” since 1993. SGL Group is the parent company of Cambridge Analytica.
Cambridge Analytica, was set up in 2013 to “combine data mining, data brokerage, and data analysis with strategic communications” for electoral processes. It was spun out of SCL Elections, and it has been said that it was funded to the tune of $15 million by Mercer. Alexander Nix was until recently the CEO, and the company is known to have been involved in performing data analysis services for Ted Cruz’s 2016 presidential campaign, for Trump’s 2016 presidential campaign and for the Leave.EU campaign in the UK. The Observer newspaper noted “for all intents and purposes SCL/Cambridge Analytica are one and the same”. Have a look at this video to see who is Alexander Nix, and how he presented the work of SCL/Cambridge Analytica at the Concordia Summit 2016. Here is Steve Bannon on Cambridge Analytica from March 2018.
The US Republican party and US right-wing politics in general is quite complex, but behind the scene SCL claims to have been deeply involved in providing directly and indirectly ‘target audience analysis’, counter propaganda, behavioural marketing, personality ‘decoding’, etc.
It is interesting to note that Steve Tatham, who worked for a while in a spin-off of Nigel Oakes (founder of SGL), wrote “that a 10% change in the behaviour of an insurgent group or hostile community would be operationally insignificant” but “a conversion rate of 10% would be outstanding and highly profitable” in commercial marketing and advertising (and I presume even more so in politics). In providing courses for NATO he argued for scientific research into behaviour predictors such as language, likes, and motivation, as opposed to focusing on creative media production ‘glitz’. I mention this here because in early 2017 SCL was contracted to perform this type of work for the US State Department’s new Global Engagement Center. The UK non-profit Bureau of Investigative Journalism produced a report on this work entitled “Fake News and False Flags” concerning how in 2004-2011 the US Pentagon paid the British public relations company Bell Pottinger over $500 million for propaganda in Iraq. Oddly enough, the first and current Managing Director of SCL Elections (the on-paper parent company of Cambridge Analytica and for whom AggregateIQ worked directly - see below) is Mark Turnbull who had worked for Bell Pottinger for 18 years.
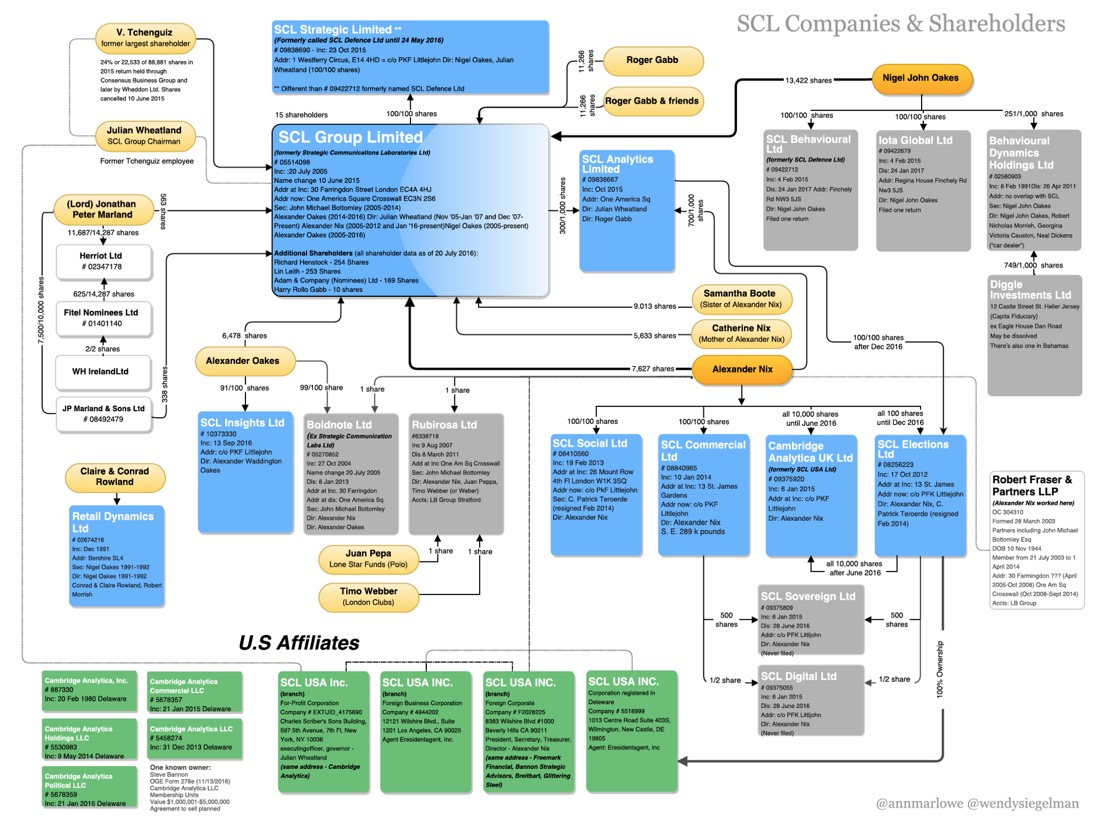
I have really only tried to simplify and summarise the contents of this TextFire article, and the above diagram shows just how complex the situation really was as of late 2016. After the revelations concerning Cambridge Analytica and Facebook I have no idea how this ‘organisation chart’ has changed.
Cambridge Analytica goes to Washington
In early 2015 Cambridge Analytica was contracted to help Ted Cruz in the 2016 Republican presidential primaries. Cruz made a credible effort, and was the final candidate to pull out of the primaries in favour of Trump. We tend to forget that in early 2015 Jeb Bush led the polls, but by early 2016 only Cruz, Trump and Marco Rubio were left in the running. In fact in 2013 Ted Cruz was only 7th in a straw poll during the annual Conservative Political Action Conference, winning only 4% of the vote. Even in 2015 only 40% of Americans knew who he was. It is said that Cambridge Analytica took Cruz out of demographics and into psychometrics. The Cruz team has admitted that their relative success was due to the intelligent use of data and analytics, and it is equally true that they paid Cambridge Analytica $5.8 million to help identify voters in the Iowa caucuses, which Cruz won. However Cambridge Analytica was considered by many Washington insiders as having a great PR machine but failing to deliver on some of the technology and analytics services and did not meet election-season deadlines. Others have said that the Cambridge Analytica core product was excellent, and what they lacked was an ability to craft the messages for the US market (in fact Cruz used Targeted Victory for their digital ad campaign). In any case this did not stop Cambridge Analytica working also for several Republican senators and congressmen in tight election races.
It is also worth noting that Cruz was backed financially by the Mercer family (him again). Mercer shifted his support to Trump after he won the Republican primaries.
After the Republic primaries Cambridge Analytica moved to New York and into the Trump presidential campaign, one that was devoid of a serious data team.
Whilst the focus here is on Cambridge Analytica and Facebook, we must understand that data analytics has been around in one form or another since Obama’s use of social media in the 2008 elections. Companies such as Civis Analytics, Platfora, and Deep Root Analytics are start-ups from that period, and data analytics was even more heavily used by Obama to rally individual voters in 2012.
Cambridge Analytica moves to New York
One of the key changes made by Cambridge Analytica in moving to New York was to install a team with a much stronger US political background. During this period Cambridge Analytica were actively promoting their services. They would buy personal data from a range of different sources, like land registries, automotive data, shopping data, bonus cards, club memberships, magazine readership, church attendance, etc. In the US almost all personal data is for sale from companies such as Acxiom and Experian. For example, if they wanted to know where Jewish women lived, they could simply buy the information, phone numbers included. Then Cambridge Analytica aggregated this data with the electoral rolls of the Republican party and surveys on social media (i.e. Facebook data) and calculated a ‘Big Five’ personality profile. Digital footprints suddenly become real people with fears, needs, interests, and residential addresses. Already in 2016 they were claiming to have profiled every adult in the US, all 220 million people.
Then it is all about customising the message for the target. You could show violence and intruders smashing windows for the highly neurotic and conscientious audience with a gun insurance policy. Or maybe a father and son at sunset, each holding guns, for people who care about tradition, habits and family.
This idea of customisation struck a cord with Trump. His array of contradictory messages became his great asset, a message for every voter. In fact one expert wrote that Donald Trump is like a biased machine leaning algorithm in that his lack of moral compass and his desire to entertain means he just follows the numbers and tries to keep his audience happy.
The Trump campaign used extensively ‘dark posts’, sponsored news-feed style ads in Facebook timelines that can only be seen by users with specific profiles. At one point in time Trumps team tested 175,000 different ad variations using Facebook. Each ad was just slightly different, and the idea was to try to focus down to individuals and customise the message just for them. One important aspect of the Trump campaign was to keep Clinton voters away from the ballot boxes. In particular the focus was on dissuading left-wingers, African-Americans and young women. This included a video of Clinton referring to black men as predators, sent to African-Americans. Another message talked about the failure of the Clinton Foundation following the earthquake in Haiti, and the target was Little Haiti in Miami.
Cambridge Analytica received $15 million from the Trump 2016 Presidential campaign. Apparently Trump’s canvassers received an app with which they could identify the political views and personality types of the inhabitants of a particular house. It was the same app provided to Brexit campaigners. The app would tell campaigners if the inhabitants were likely to be receptive, and there were even conversation guidelines for different types of personalities. Clinton campaigners had a similar type of app. Where Cambridge Analytica came in was expanding the personality types and focussing only on 17 US states. They found that a preference for US made cars was the best indicator of a potential Trump voter. Also they collected feedback showing which message worked best and where.
Just how effective is this approach? Evidence is at best incomplete. But Ted Cruz did increase his scores in rural areas. Fewer African-Americans voted for Clinton. Trump won by spending less money. He avoided costly mainstream TV advertising in favour of digital personality-based advertising. He targeted swing-states where his message would have the greatest impact.
Some have noted that statisticians both won and lost the US Presidential elections. Demographic lost, and psychometrics won. He who scorned scientific research, won using a highly scientific approach in his campaign.
I am not going to dive into the Channel 4 News undercover investigation which revealed that the then Cambridge Analytica’s CEO Alexander Nix offered to use dirty tricks, including the use of bribery and sex workers, to entrap politicians and subvert elections.
Split-second analytics are all about money
Here I am going to take a few minutes off here and add a bit about the US Senate hearing in 2014 entitled “Abuse of Structured Financial Products: Misusing Basket Options to Avoid Taxes and Leverage Limits”. The basic premise was that some financial institutions designed a complex financial structure to abuse or violate US tax statutes and regulations. Deutsche Bank and Barclays made the ‘basket options’ and sold them to two hedge funds, Renaissance Technologies and George Weiss Associates, who then used them to avoid federal taxes on buying securities with borrowed funds (down from a 35% tax to just 15%).
We are interested here for two reasons. The first is that Robert Mercer (whom we have read a lot about) was until recently co-CEO of Renaissance Technologies. Mercer has been mentioned here for his strong support of the Republican Party, and for being involved directly with Cambridge Analytica. In a kind of poetic justice, the founder of Renaissance Technologies, James Harris Simons, is a major contributor to the Democratic Party. Oddly enough Mercer originally worked in the field of artificial intelligence and statistical machine translation, whereas Simons worked in the field of pattern recognition and string theory.
The second reason we are interested in these hearings is that what we are actually talking about is algorithms for statistical arbitrage that focus on tiny and very brief pricing anomalies of publicly-traded assets. These differences are really only visible to computer system that execute more than 100,000 trades a day. High-frequency trading is really a package of techniques. This is not about short-term market forecasts, but about buying and selling securities based upon a set of long-term predictions. It is also about having the best computers, the most bandwidth, and being physically next door to the stock exchanges (shortest fibre-optic cables). And it is also about collecting a massive amount of data, stories, reports, regulatory filings, quotes, trades, from all over the world. All with the idea to make predictions about future price changes. One part of all this is the so-called Firehose, a way to stream pure social media output from all the major social media companies (Facebook, Twitter, etc.) into a set of harvesters and near-real-time analytics, and finally into stock trades (or in some cases ad purchases). The key in all this is zero ongoing administration, everything must happen automatically and instantaneously from ingestion to buy and sell.
For those who have not heard of the Firehose, its worth remembering because it is also an element in the emerging ‘Internet of Things’ where millions of sensor data must be fused together in real-time and where action and reaction must be split-second automatic.
I included here this little digression because we are always talking about Big Data, algorithms, analytics, social media, and all with the aim to overcome imprecision, whether it be buy-sell predictions or voting sentiments.
Cambridge Analytica and AggregateIQ (and Brexit)
It is well known that Cambridge Analytica worked for Leave.EU, but it has also been suggested by The Guardian that they worked indirectly for Vote Leave (campaigns are forbidden by UK law to coordinate activities). Vote Leave, the official Leave campaign, spent more than half of its official £7 million campaign budget (tax-payers money) with a Canadian company AggregateIQ. Oddly enough AggregateIQ had (at that time) the same address and phone number as Cambridge Analytica’s Canadian office, SCL Canada. Proof of this was provided to a UK Select Committee by the whistleblower Christopher Wylie who also confirmed that AggregateIQ was just a group of coders and developers he knew in Canada. Proof was also provided that AggregateIQ and SCL had an intellectual property agreement and a revenue-sharing clause (all AggregateIQ intellectual property is assigned to SCL Group). It has been suggested that the Leave campaign had more cash than it was legally allowed to spend and that it illegally funnelled money to AggregateIQ through other Brexit groups (the total Leave spend with this company was £6.8 million). For example it has been reported that Vote Leave donated £625,000 to a pro-Brexit grassroots student group BeLeave, and the money ended up with AggregateIQ (there is evidence that shows that the money did not even go through the hands of BeLeave, but went directly to AggregateIQ). It must be said that much of the money given to AggregateIQ was actually spent on contracting online advertising.
Shahmir Sanni, former treasurer of BeLeave, told The Guardian and Channel 4 News that Vote Leave, the official campaigners for Brexit, sidestepped election spending rules. It is alleged that Vote Leave funnelled money to Cambridge Analytica and on to AggregateIQ through BeLeave. AggregateIQ has said that it is not a direct part of Cambridge Analytica and was not involved in exploiting Facebook data. This contradicts the evidence provided by Christopher Wylie, the whistleblower from SCL/Cambridge Analytica.
Recently Gizmodo has written that AggregateIQ actually created Cambridge Analytica’s campaign-management software, the so-called Ripon platform used first by Republicans in the 2014 US mid-term elections, and later in the 2016 Republican presidential campaign (one campaign source said that the software actually never worked). Ripon is a town in Wisconsin, where the US Republican Party was founded in 1854. Knowing that AggregateIQ is a wholly owned Canadian company, US law says that foreign nationals must not “directly to indirectly participate in the decision-making process” of a political campaign. A complaint has been filed with the US Federal Election Commission. However there are reports suggesting that Ripon was never actually used (here is a 16-page copy of the Cambridge Analytica’s ‘Ripon’ brochure). The Ted Cruz 2016 campaign is supposed to have relied on more traditional data sources, and the data from Facebook was actually kept outside the firewall of Project Alamo, the data platform used by the Trump campaign.
UpGuard has published two extensive reports on what was found on AggregateIQ servers (part one, part two). I quote here UpGuard because it gives the reader an idea about the level of technical sophistication of modern-day political campaigning. “Revealed within this repository [of AggregateIQ] is a set of sophisticated applications, data management programs, advertising trackers, and information databases that collectively could be used to target and influence individuals through a variety of methods, including automated phone calls, emails, political websites, volunteer canvassing, and Facebook ads. Also exposed among these tools are numerous credentials, keys, hashes, usernames, and passwords to access other AIQ assets, including databases, social media accounts, and Amazon Web Services repositories, raising the possibility of attacks by any malicious actors encountering the exposure”. The files are now offline.
Facebook User Data and Brexit
Quite recently new reports have emerged concerning both the number of user profiles exploited, and the number British profiles that might have been exploited in the lead up to Brexit. Facebook has now confirmed that they provided to Cambridge Analytica data on 87 million users, including just over 1 million British. Cambridge Analytica continues to say they received data from Global Science Research only on 30 million US users. There are reports that in the initial buildup to Brexit Cambridge Analytica had interviewed nearly half a million Britons, and had decided to target ‘Middle Britain’ and the poorer, less well-educated, who traditionally were both anti-EU and less likely to vote in local and national elections. Vote Leave did not use Cambridge Analytica for their campaign, but they did spend a substantial portion of their allowed budget with AggregateIQ. In fact Alexander Nix, boss of Cambridge Analytica at the time, said they did not provide any services to any Brexit campaign. But the business development director for Cambridge Analytica said that they were involved in providing data analysis services to UKIP, and they briefed Leave.EU on the results of their earlier research.
The whistleblower Christopher Wylie and SCL
We have mentioned Christopher Wylie, the 28-year-old whistleblower from SCL/Cambridge Analytica several times. He originally leaked documents to reporters showing that the company had improperly gathered its data from the profiles of 50 million Facebook users, the vast majority of which had not consented to making their information available. Later he testified to a UK parliamentary committee that he helped set up both Cambridge Analytica and Canadian-based AggregateIQ, which was also called SCL Canada. AggregateIQ is based in his home town, and the two directors were his friends. He called AggregateIQ a franchise of the SCL Group. Wylie also confirmed that AggregateIQ built a software engine called Ripon in order to target voters on behalf of Cambridge Analytica and that this was then populated with data harvested from Facebook.
The committee has now published 122 pages of documentation supplied by Wylie that back up his claims. These include contracts whereby AggregateIQ agreed to build the Ripon system for Cambridge Analytica SCL Elections and then license intellectual property back to SCL Elections.
Privacy - is Cambridge Analytica the ’thin end of the wedge’?
Collecting data on people is not new. As far back as 1841, Dun & Bradstreet collected credit information and gossip on possible credit-seekers. In the 1970’s, list brokers offered magnetic tapes containing data on a bewildering array of groups: holders of fishing licences, magazine subscribers, or people likely to inherit. According to the US Federal Trade Commission the big data brokers, Acxiom, Experian, Quantium, CoreLogic, TransUnion, LifeLock (ex-ID Analytics), hold as many as 3,000 data points on every US consumer, and according to consumer groups only “50% of this data is accurate”. Frederike Kaltheuner, of the lobby group Privacy International, noted that more than 600 apps have had access to her iPhone data over the last six years.
For at least 10 years privacy experts have been issuing warnings about the exploitation of personal data by social media platforms and search engines (have a look at the 2006 Report on the Surveillance Society and the 2017 report from Cracked Labs How companies use personal data against people). And we are not just talking about the 2013 revelations of Snowdon on state espionage. For example ProjectVRM (VRM means vendor relationship management) was started in 2006 to promote tools that put consumers in control of their relationship with vendors. The project has its roots in the 1999 Cluetrain Manifesto which issued a series of theses including “markets consist of human beings, not demographic sectors”. But the reality is that there have been privacy scandals before, and nothing happened. In 2010 Google was found collecting Wi-Fi data with their Street View cars, but everyone had forgotten it a month later. In Sept. 2017 Equifax was breached and the social security numbers, birth dates and the addresses of 143 million Americans were stolen. Does anyone remember that?
Hidden behind the Cambridge Analytica and Facebook story (scandal?), we hardly noticed a different story about YouTube (read Google) illegally collecting data from children (USA Today, 9 April, 2018) and then targeting them. Already in late 2017 YouTube pulled ads on 2 million inappropriate children’s videos (The Verge, 28 Nov. 2017). That included switching off commenting on 625,000 videos targeted by child predators. There is a chance we remember this, but do we know what happened afterwards? So far all Google did was to stress that ads sold in YouTube Kids (this is really designed for children under 13 years old) include additional advertising policies. Consumer groups have filed a complaint to the US Federal Trade Commission. If you are one of the few people who still believe the Google mantra “Don’t be evil”, then you had better read “Worried about what Facebook knows about you? Check out Google” from NBC News, 29 March, 2018.
And if this was not enough, according to The Guardian (4 April, 2018) Grindr has been collecting data on its members (gay men) which included their location and HIV status, and now it would appear that this information is being shared with third parties. The social media platform said that it was ‘industry practice’ to share data with partners to test and optimise its platform.
Facebook is not the only company that develops detailed profiles about consumers and allows them to be used for commercial and political targeting. This has been going on for years, across a multitude of industries. The current scandal merely pulled back the curtain on a common practice that the industry doesn’t like to talk about. The reality is that the wholesale collection, use, and sharing of data with third parties remains largely unregulated, uncontrolled, and conducted in secret. Everyone goes online, uses a smartphone, drives in a smart car, uses a smart watch, or relies on other products that may lack the safeguards needed to protect users’ private information and personal security.
Each day, connected devices track our location, our online searches, the friends we contact, the things we buy, and even what we say in the privacy of our homes. Each day, thousands of data brokers sell information about our finances, politics, religion, race, and personal habits to anyone willing to buy it, including scam artists that use the information to trick and defraud us. Medical websites are still able to sell our private searches about cancer, Alzheimer’s disease, and depression to anyone willing to pay. And companies are increasingly using data to charge different consumers different prices.
Service providers and social network owners still think that advertisers are their customers, and users are the product. An apps consumer front-end is just a conduit through which users willingly share their personal information. Information is collected and sold to third parties who have no stake in the underlying interpersonal relationships. Today they have no motivation or compelling reason to change a system that works and is highly profitable. So until society find ways to ensure a closer alignment between the business interests of tech companies and the privacy interests of consumers, there will be more stories like the ones mentioned on this webpage.
Consumer data, our likes, dislikes, buying behaviour, income level, leisure pursuits, personalities and so on, certainly helps brands target advertising dollars more effectively. Does that mean that as consumers we are better informed and that products and services are cheaper? Is that data being used to provide cheaper credit cards and mortgages, and help us pass employment background checks more easily and find new, better paid jobs? Or is it being used to discriminate against minorities, against those with health problems, and those who are socially isolate and having difficulties in life?
For those readers who are interested check out this 2015 report What is the Future of data sharing? by Columbia Business School on behalf of AIMIA, a data-driven marketing and loyalty analytics company.
Some groups argue that all this has become an issue of personal security and safety. And just as we needed safety laws for seat belts and cigarettes, we need common-sense laws for online privacy.
Today privacy policies are buried in Terms of Service. Two researchers at Carnegie Mellon University worked out that to read every privacy policy an average person comes across online, would take 76 days, reading eight hours a day. Why don’t companies post easy-to-understand information about their data practices in a way that allows consumers to compare companies’ practices? Consumers should have an easy way to say ‘yes’ or ‘no’ to the way data is used and for data shared with third parties. Certain types of usage could be prohibited altogether, like using information about our medical conditions or treatments for marketing. Collected data must be protected, and users must have more control over what data is collected, and they should be able to delete their entire account and permanently eliminate their data if they choose to. There should be a strong authority for robust enforcement, including the ability to levy sizeable fines for violations.
Alternatives could be even more draconian. Some experts have suggested to treat social media platforms as information fiduciaries and impose legal obligations on them as we do with lawyers and doctors who are privy to some of our most personal private information (check out the blog of Jack Balkin, professor at Yale University Law School). Others want services such as Google and Facebook declared as public utilities and regulated like electricity or phone services. Yet other experts have suggested to simply classify Facebook as a monopoly and break it up.
An additional background feature to this story is the fact that the EU-wide General Data Protection Regulation (GDPR) will come into force in May 2018, and it addresses the issue of sharing personal data. Whilst this new regulation is a key one in the European context, it is also a complex topic with far-reaching implication that can't really be addressed on this webpage. The UK’s Independent Commissioner’s Office has a whole series of webpages dedicated to GDPR. To get a better view of GDPR have a look at the videos on Legal obligations and responsibilities for data processors and controllers under the GDPR, GDPR Remediation Projects Where to Begin and (Still) Beat the Deadline and Locating & Managing EU Personal Data for GDPR Compliance.
According to this report Facebook account holders are being sent one of two emails informing them whether their data was breached. I have not received mine yet!
Concerning privacy setting in Facebook, check out these links:
How to Take Control of Your Facebook Privacy Settings, the MacObserver, 29 Jan. 2018
The Complete Guide to Facebook Privacy Settings, Techlicious, 20 March, 2018
Facebook Privacy Settings: 18 changes you should make right away, Trusted Reviews, 21 March 2018
The only way to be truly secure on Facebook is to delete your account.
Is leaving Facebook the only way to protect your data?
Before doing anything download your Facebook data, then you can deactivate your account, but that does not mean deleting it. If you look carefully you will find that a delete can take up to 90 days, and if you log back in the days following a deletion, then the deletion is cancelled. Sounds simple, but it is worth looking at delete in more detail (How to DELETE Your Facebook Account (REALLY!) – 2018 Update).
As a last word, some experts go beyond the simplistic equation Facebook ≠ Privacy. They think that with Google, Twitter, Facebook,… and their ‘pure and blameless data’, we as a society are going to lose not just privacy, but identify, moral reasoning, norms and rules for collective agreement, political integrity (did it ever exist?), and even the functions of democratic sovereignty.
Some additional references
The great British Brexit robbery: how our democracy was hijacked, The Guardian, 7 May 2017
A Special Relationship & the Birth of Cambridge Analytica, Textfire, 18 May 2017
Inside Russia’s Social Media War on America, TIME, 18 May 2017
GOP Data Firm Accidentally Leaks Personal Details of Nearly 200 Million American Voters, Gizmodo, 19 June 2017
Pro-Russian networks see 2,000% increase in activity in favour of Catalan referendum, El País, 1 Oct. 2017
There’s fake news in Catalonia too, El País, 2 Oct. 2017
Government confirms intervention of Russian hackers in Catalan crisis, El País, 10 Nov. 2017
Russian network used Venezuelan accounts to deepen Catalan crisis, El País, 11 Nov. 2017
How the Russian meddling machine won the online battle of the illegal referendum, El País, 13 Nov. 2017
Facebook Is Shutting Down Its API That Marketers Lean on for Research, Adweek, 1 Dec. 2017
What Trump still gets wrong about how Russia played Facebook, Wired, 17 Feb. 2018
How Russian networks worked to boost the far right in Italy, El País, 1 March 2018
Bad actors are using social media exactly as designed, Wired, 11 March 2018
Here’s how Facebook allowed Cambridge Analytica to get data for 50 million users, Recode, 17 March 2018
How Trump Consultants Exploited the Facebook Data of Millions, The New York Times, 17 March 2018
One Way Facebook Can Stop the Next Cambridge Analytica, Slate, 18 March, 2018
Meet the Psychologist at the Center of Facebook’s Data Scandal, Bloomberg, 20 March 2018
Promises, Promises: Facebook’s history with privacy, Phys.org, 30 March 2018
Facebook-Cambridge Analytica: A timeline of the data hijacking scandal, CNBC, 10 April 2018
On Facebook, Zuckerberg gets privacy and you get nothing, ZDNet, 10 April 2018